Day 8
For part 1 we’re given a list of instructions, one per line, with 3 possible actions taken. Either we alter a value and move on to the next instruction, we move to a different instruction, or skip and move on to the next line. Not too bad, I can set up a $skip variable, such that when jumping forward the instructions aren’t read and then simply print out the value of the accessor once processing the filehandle is finished. Except the jump instruction also takes negative values => trying to readlines from before sounds like a headache for future Juan. Today I just want a solution, not necessarily an efficient one. The first idea is to get this into a hash of hashes such that as each line is read, an index key is paired with another hash containing 3 key-pair values: {'action':$act, ' 'val': $value, 'exec':0}
Now once the data is nicely in the hash of hashes, it needs to be processed. The first thing is to establish the break point to avoid the infinite loop.
if ($instructions{$index}{exec} == 1){
print ($acc, "\n");
die; #exit the loop
}
Next up was running actually doing the tests which meant testing all keys in order was out of the question. The first index seemes to always be 1, so doing it with a while loop means propper control can be implemented:
$max = keys %instructions;
$id = 1;
while ($id < $max){
# infinite loop control from before
#
# check if the actions are jump or acc
# and do something
# else $id++
}
Most likely it was an error with execution, but this was dying 1 instruction too early. Refactored everything so now data was in an array of arrays.
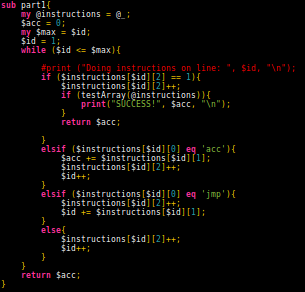
Part 1 worked fine with no issues. Giving the answer incredibly fast. Part 2 on the other hand, required testing possible mutations of the base instructions. Clearly this means I need to test the array once the instructions are processed. Convert the solution for part 1 into a subroutine as above, and then add a test to verify if no single instruction was used more than once.
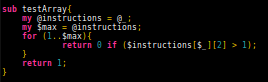
From there it was just a matter of controlling the mutations. Or so I thought.
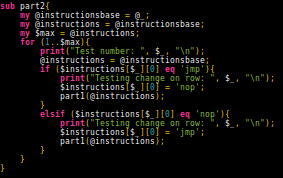
Need to ensure an immutable copy of the instructions is kept [X]
Check if the given instruction causes problems [X]
Test the new array [X]
Find the result [ ]
Debugging shows the control works most of the time. However at a certain point, instead of returning $acc the code seems to enter an infinite loop. Something to check in the future.
Day 9
Todays challenge involved testing a data stream for errors. Each line contains a number and following an introduction buffer, each new number has to be the sum of 2 numbers from the previous buffer. My initial thoughts were to hard code the buffer, but that was misreading the question. Once the buffer for the checks is in place, each new item gets added to the list, and the oldest gets discarded. Fairly simple, can be done while processing the input data: check that the first 25 get read in, then start processing.
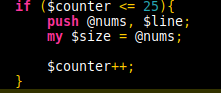
Processing for part 1 consisted of checking in a nested loop for each item. To avoid doing 252 checks, the moment a solution was found (multiple solutions possible) it would break the loop. Following the data processing, if no solution had been found, it would print the number and die as I no longer needed to process additional data.
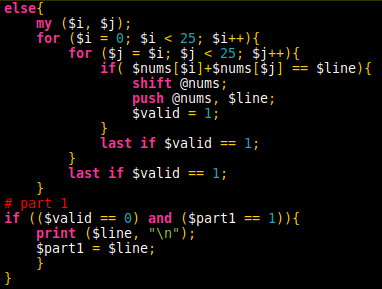
For part 2, it was important to find a continuous list of numbers within the entire datastream such that together they added to the flag in part 1. I didn’t want to change the code from part 1 as it may come in handy later on in the advent, so new array @nums2 holds every item from the list.
Now I want to check every possible set of continuous numbers, without leaving the machine running until the 25th. The question implies there are 2 numbers, which means the largest starting index is 2 less than the size of @nums2. (-1 as array counting starts at 0, -1 as the last array holds $nums[-2] and $nums[-1]). That’s the initial for statement sorted. There are 2 critical breaking points:
- The starting number in the list is greater than the key from part 1
- The sum is greater than the key found in part 1.
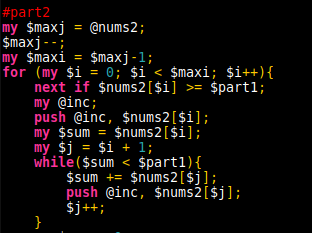
Solved part one by using the next if, and the second with the while ($sum < $part1) control. For some reason I created the @inc array (for included numbers) and forgot about it while trying to finish part 2. Attempted splicing the @nums2 array but somehow kept getting the wrong highest number. Most likely an indexing issue with the splice function. Used the @inc array and suddenly it worked.
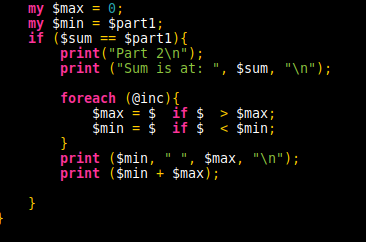
As I look at this now, I realise the foreach (@inc) could have been replaced with
sort @inc; my ($min, $max) = ($inc[0], $inc[-1]); # or accessed those values directly
Hindsight is, as always, 20/20.