Why Open source
From a business perspective, Open Source is appealing due to the software being available for free. Obviously this comes with the caveat, free as in puppies; not free as in beer. While open source software can be copied and used with minal (if any) cost, configuring and maintaining will be an in-house task. Despite this internalised cost, there are other elements that make open source software appealing: multiple contributors leads to faster development of required/requested features; higher security and therefore a much larger return on investment. Although it is debateable whether open source software provides higher security, it has been a driving factor for many companies now selling support rather than software liscences. (Red Hat, Canonical…) On the personal side, there is also an element of involvement. When there is a tool you use regularly, it becomes quickly apparent which features are missing. It is possible to request these, but the developpers usually maintain these tools in their spare time meaning it’s difficult to implement all features while maintaining secure code.
So why not just make your own copy with the required feature? 4 simple steps:
- Fork the code (make an online copy that is yours)
- Clone that code onto your system
- Implement the thing (and test the thing)
- Tell the developper you implemented the thing
Automation
While most programming languages will provide you with libraries to fulfil any peculiar needs you may have, there already exists a ready built solution which is more robust than the 10 lines of code you may be throwing together in an attempt to solve a problem. I had wanted to automate son enumeration tools, namely Sherlock and WhatsMyName. I’d used these tools in the past, but they have too many common entries and false positives. The first step was to attempt automating sherlock so that a simplified command would execute it with all the necessary flags (output file etc. etc.).
Sherlock played nice, WhatsMyName however, did not. WhatsMyName only returned positive entries to the shell (or STDOUT) and would not accept alternate filepaths for its own database. It required some research for specific syntax of some packages, but within a rather short timeframe I had a version of the software that provided added functionality: writing to a file & using a different file from default for testing. I let the maintainer know (pull request) and to my surprise it was accepted within 3 hours.
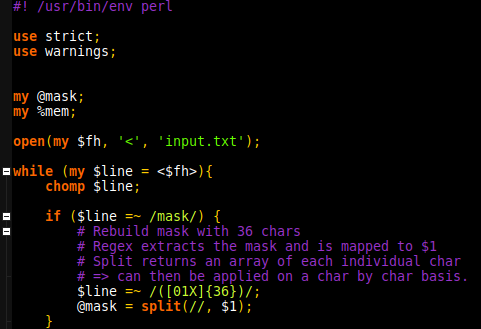
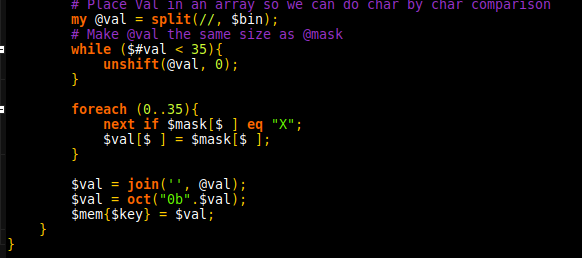
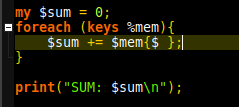
Now that I had sherlock and WhatsMyName automated to output to a specific folder, the next step was analysing for unique entries. I was able to do this with a short perl script which takes advantage of hash tables to test for duplicates. With a known username the list went from 86 entries combines to 65 unique. Sadly, when testing the sites in a browser, many rendered a 404 page. Fortunately, open source meant I could quickly test these with existing solutions, in this case HTTP::Tiny. 65 Unique entries went down to 61. Back in 2012 when I was learning perl, I’d had to write web scrapers as part of the larning process. I could parse the sites looking for “user does not exist” or similar. Except, there is yet another far more robust solution.
EyeWitness will take a list of URLs and provide a screenshot of the page. This means if the profile exists I can quickly verify its authenticity, and if it does not exist can quickly eliminate it without needing to do any additional parsing. Full automation.
The crutch
Although Open Source empowers users to becomes creators and make the tools they use, it does have one major inconvenience: Liscencing. Each developper, or development team gets to pick how future users can use, alter or deploy their tool. In most cases it is a simple case of “Let the user know we created this and it’s cool” but other teams want to keep a tighter control of how their solutions are used. When you keep your versions isolated from the public in the most there are no problems, but when inviting others to expand capabilities it does become a different ball park.
To Open Source or no to Open Source
For the majority of use cases, Open Source will provide a solution which works out of the box. There can be configuration issues, but this comes with the reduced cost. For a solution making development accesible and inclusive to an increasingly large audience, the liscencing issue seems almost trivial. Time will tell. The only case I can still see for use of closed source software remains ERP specific solutions, where the code base is so large making it public exposes the codebase to more security risks than it covers.