Day 14
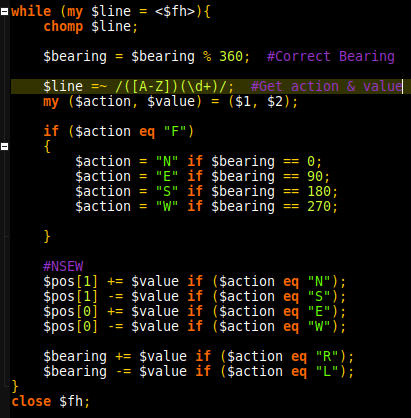
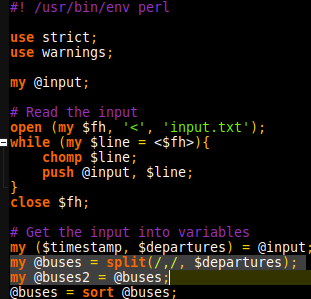
The days challenge starts explaining that a binary representation needs to be observed with a filter, and then the new representation stored in a specific place of memory. It is not mentioned at any point that memory is full, suggesting that a hash table will allow for the best way of storing the values. The first roadblock is accessing the elements of the mask, this is made easy by using split and storing the mask as an array.
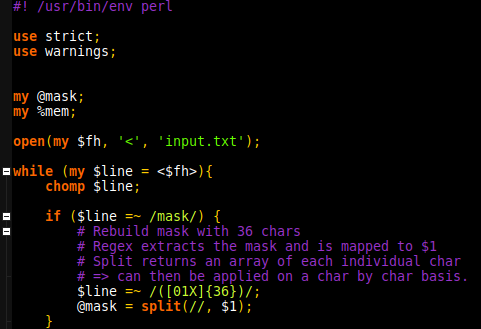
There are 2 possibilities. Either the mask is updated, or a value is stored in memory. After chomping the line, we immediately check if it is a mask instruction. If it is a mask instruction, we extract the 36 characters by extracting the match to 36 adjacent characters composed of 1, 0 and X. The extraction is then split into @mask (declared outside of scope because… scope.
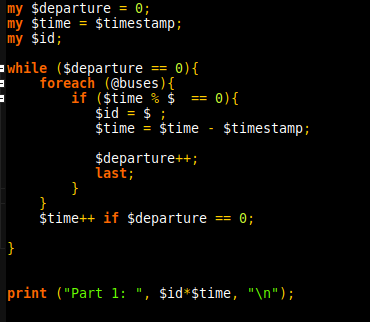
The second part didn’t allow for 2 greedy matched. $line =~ /(\d+).*(\d+)/ only matches the first digit of the second pattern. Overcame the issue by using substitutions and matching twice with $1.

As the value is given in decimal, sprintf provides a string representation of the binary. From there it’s split into an array, and 0s added to the front until it is the same size as the mask. Given that the value can have different sizes, using the last index of the array as the control allows to verify the size without calculating the size. Finally, conversion back in decimal is done using the builtin oct function.
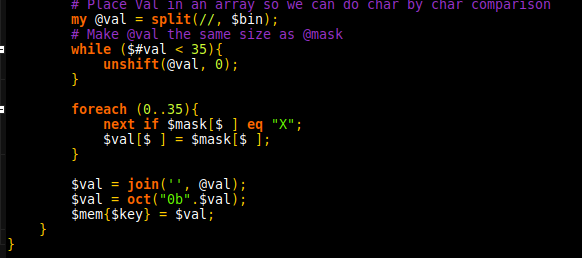
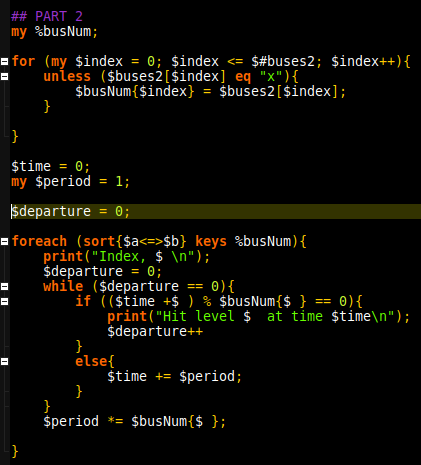
Finally, find the sum of the values using a simple foreach loop:
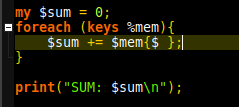
The main challenge here was working with decimal and binary representations and changing between them. Additionally, because of the binary numbers are not stored as strings, analysing them on a character by character basis meant converting into an array of chars. Highly similar to a C representation.
Link: https://github.com/jspinel/AdventofCode/tree/main/2020/14