Day 6
This day’s challenge required doing some text analysis. Ok, I’d done this in the past as a part of language analysis to measure changes in language over several hundred years. The first part required finding how many questions people answered yes to, from a list of 26 questions… 26 questions, 26 letters. Yep, hardcoded it:
@alphabet = ("a".."z");
Then analysed the text by splitting on empty lines and processing responses with some simple regex:
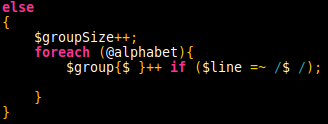
Using the hash table has the advantage that even if several people answer the same questions, the letter is only used once as a key in the hash table. So, once a group’s answers have been processed and the text finds an empty line, that data needs to be processed:
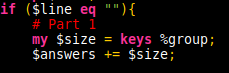
Once all data is read in, a simple print($answers, "\n"); gives the answer. Part 2 then requires finding those questions where everyone answered yes. For this I’m using an additional value, $groupSize which is incremented at each answer sheet and reset to 0 after processing. This way, upon processing the results, it is easy to compare how many elements in the response data have $groupSize as their value.
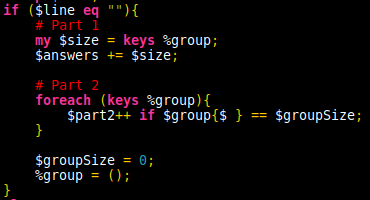
While the script was rather short while readable, this task was far from trivial. The past experience was an incredible boost in establishing the best data structure to go with.
Day 7
Reading the requirements immediately reminded me of some applied maths concepts. Specifically, unordered graphs. Fairly simple idea, create a node such that the node has a name and either it has contents or it has no contents (end node). Given each row of data was providing the information, it was fairly simple to create the nodes. Creating the graph interface on the other hand, was a whole other nightmare and importing the module was also a further rabbit hole not worth the limited time available for the challenge. Ok, so simply making it a hash of hashes. I can take advantage of regex and controls to make hash tables of varying sizes.
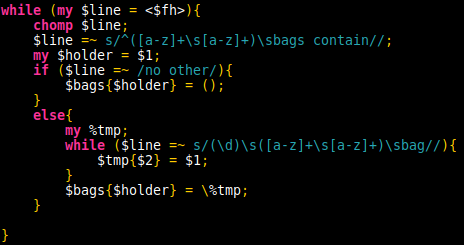
I was able to verify the %bags hash contained the data in the expected and wanted format by using Data::Dumper. Unfortunately after a couple hours it felt as though I’d forgotten how recursion worked, as the ouput I was seeing in terminal suggested an infitnite loop. Definitely a topic I’ll be going back to later on, when there is time.
